2020-07-09
Amazon S3 の仕様とユースケースについてあらためて調べてみた
Amazon S3 について説明する機会があり、あらためて仕様とユースケースについて調べたのでブログ記事としてまとめてみました。
概要
前提
AWS のストレージサービス Amazon S3 がどういったサービスなのか、公式ドキュメントの内容をもとにして自分なりに仕様とユースケースについてまとめてみます。
CloudFront のキャッシュ仕様に引き続いて、あらためて調べてみたシリーズ(?) です。
Amazon CloudFront のキャッシュ仕様についてあらためて調べてみた
Amazon S3 の概要
Amazon Simple Storage Service はインターネット用のストレージサービスです。また、ウェブスケールのコンピューティングを開発者が簡単に利用できるよう設計されています。
公式ドキュメントにはこのように説明されています。
既存のサーバにマウントするわけではなく、 AWS CLI や SDK を用いてデータにアクセスします。(マウントしたように扱うことができるサードパーティのツールも存在しますが、今回は純粋な S3 の説明ということで触れません)
インターネットに公開されたストレージなので、格納したデータには https://examplebucket.s3.us-west-2.amazonaws.com/images/sample.jpg のような URL でアクセスすることができます。できてしまいます。後述しますが、データへのアクセス権限設定を誤ると誰でもアクセスできてしまうので注意が必要です。
用語の説明
S3 の詳細な説明の前に、このあと出てくる用語の説明です。
バケット
S3 にデータを格納するためのコンテナ (名前空間) のことです。バケット名は、全 AWS アカウントおよび全リージョンを通じて一意な値となります。
オブジェクト
S3 に格納するデータそのものです。 S3 に格納されると言っても、いずれかのバケットに格納されるという意味です。
キー
バケット内のオブジェクトの固有の識別子です。
リージョン
バケットを保持するリージョンです。そのバケットを使用するサービスの地理的な条件や、複数リージョンへのオブジェクトの分散など、使用用途に合わせてリージョンを選択します。
これらの情報は上で挙げた https://examplebucket.s3.us-west-2.amazonaws.com/images/sample.jpg にすべて含まれています。
examplebucket がバケット名、 us-west-2 がリージョン、 images/sample.jpg がキー、 sample.jpg がオブジェクトとなります。
セキュリティ
上にも書いたように、 S3 に格納されたオブジェクトにはインターネット上からアクセスすることができます。できてしまいます。(大事なことなので)
そのため、適切にアクセス権限を設定しておかないと情報漏えいの危険もあるということです。
とは言っても、現時点 (2020/07) では新たに S3 バケットを作成する際、デフォルトでバケットとオブジェクトへのパブリックアクセスはすべてブロックの設定となります。そのため、インターネットからはアクセスできず、 AWS CLI や SDK (以下、特定のアプリケーション) からのアクセスのみ可能となります。
しかし、後述する S3 の機能である 静的ウェブサイトのホスティング を利用する場合はどうしてもパブリックアクセスを許可する必要があり、 IP アドレス等によるアクセス制限をしたい場合があります。また、パブリックアクセスは無効にしていた場合でも、特定のアプリケーションからのアクセス方法を制限したい場合もあります。(オブジェクトの読み取りだけ可能、など)
そのような場合には バケットポリシー と呼ばれる JSON 形式の設定により、アクセスを制御します。下記がバケットポリシーの例です。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::examplebucket/*",
"Condition": {
"IpAddress": {
"aws:SourceIp": [
"1.xxx.xxx.xxx/32",
"2.xxx.xxx.xxx/32",
"3.xxx.xxx.xxx/32"
]
}
}
},
{
"Effect": "Deny",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::examplebucket/*"
}
]
}詳細な説明は省略しますが、上記のバケットポリシーでは examplebucket バケットに対して特定の IP アドレスからのみアクセスを許可しています。
デフォルトではパブリックアクセスはすべてブロックとなりますが、要件によっては部分的に公開する必要があったりするので、その際には適切にアクセス権限を設定する必要があります。
その他、 S3 のセキュリティに関しては公式のドキュメントも参照してください。
また、先日 IAM ポリシーの Condition で S3 バケットへのアクセスを制御してみた記事も書きました。
IAM の Condition によるアクセス制御を試してみる
ストレージクラス
S3 には様々な性質のオブジェクトを格納する場面があります。例えば、静的サイトのように高頻度でアクセスされるオブジェクト、逆に、過去のログファイルのように頻繁にアクセスする必要はないがいつか必要になる時が来るオブジェクト のような性質です。
これらの性質に合わせて、 S3 には次のような ストレージクラス が提供されています。
- 汎用/低頻度アクセス
- S3 標準
- S3 Inteligent-Tiering
- S3 標準 - 低頻度アクセス
- S3 1 ゾーン - 低頻度アクセス
- アーカイブ
- S3 Glacier
- S3 Glacier Deep Archive
上の例で挙げた静的サイトやその他 頻繁にアクセスする必要があるオブジェクトは S3 標準 クラスを利用し、あまりアクセスすることがないオブジェクト、アーカイブとして残しておきたいオブジェクトなどは、リストの下の方にあるストレージクラスを使用します。
ストレージクラスによる違いは、主に 可用性 、 取り出し時間 、 料金 です。
“S3 標準” クラスは一番可用性が高く、発生する料金も一番高いです。逆に “S3 1 ゾーン - 低頻度アクセス” クラスでは可用性は低くなりますが、発生する料金は S3 標準に比べて安くなっています。
また、アーカイブ用のストレージクラスでは発生する料金が大幅に安くなりますが、格納したオブジェクトの取り出しに 数分 〜 数時間 かかります。長期保存が必要なデータの保持には、アーカイブ用のストレージクラスを利用することでコストの削減になります。
その他の違いや可用性の細かい値については公式ドキュメントを参照してください。
料金
S3 を利用する上で発生する料金は、次の 4 種類あります。
- ストレージ
- リクエストとデータの取り出し
- データ転送
- マネジメントとレプリケーション
マネジメントとレプリケーション については S3 の機能の中でも Advanced な機能に対して発生する料金なので、今回は説明を割愛します。それ以外の 3 種類について、それぞれどのような料金が発生するのか確認してみます。
また、前項でストレージクラスによって料金が変わると書きましたが、ここでは S3 標準 クラスの東京リージョン (ap-northeast-1) での料金について触れます。
ストレージ
S3 バケットに格納しているオブジェクトの 合計サイズ に発生する料金です。
| 料金 (1 GB あたり) | |
|---|---|
| 50 TB まで | 0.025 USD |
| 50 TB を超えて 500 TB まで | 0.024 USD |
| 500 TB 以降 | 0.023 USD |
例えば、オブジェクトのサイズ合計が 300 TB あった場合の料金は次のようになります。
(50 * 1024 * 0.025) + (250 * 1024 * 0.024) = 74241 USD = 105 円とすると、毎月 779,520 円 の料金が発生することとになります。
リクエストとデータの取り出し
S3 バケット内のオブジェクトに対する リクエスト回数 に対して発生する料金です。
| リクエストの種類 | 料金 (1000リクエストあたり) |
|---|---|
| PUT, COPY, POST, LIST | 0.0047 USD |
| GET, SELECT, その他 | 0.00037 USD |
AWS CLI や SDK からのリクエストはもちろんですが、マネジメントコンソール上でオブジェクトを閲覧する際にも GET リクエストとしてカウントされます。ただ、 GET, SELECT などの読み取りに関するリクエストに関しては料金単価が非常に低いので、あまり意識する必要はないかなという印象です。
データ転送
S3 とパブリックなインターネット、及び他の AWS サービスとの間に発生する データ転送量 に対して発生する料金です。ただし、次のデータ転送については料金が発生しません。
- インターネットから S3 へのデータ転送
- S3 と同一リージョンにある Amazon EC2 インスタンスへのデータ転送
- Amazon CloudFront へのデータ転送
なので、料金が発生するデータ転送のパターンとしては次のとおりです。
- S3 からパブリックインターネットへのデータ転送
- S3 から別リージョンにある他の AWS サービスへのデータ転送
インターネットへのデータ転送については、後述する静的サイトのウェブホスティング機能や、バイナリのダウンロード用にオブジェクトの URL を公開しているときには注意したいです。
別リージョンにある他のサービスへの転送については、たとえ同じ国であってもリージョンが違えば発生します。なので、東京リージョンと大阪リージョン (ローカル) 間でも料金が発生します。
S3 ではこういった場面で料金が発生します。その他、料金の詳細については下記の公式ドキュメントを参照してください。
Amazon S3 のユースケース
では、実際に S3 をどのように使うかを紹介していきます。
容量無制限のストレージ
S3 の最大の特徴は、やはり 容量無制限 という点です。各オブジェクトの最大サイズは 5 TB となっていますが、バケットの合計サイズには制限がありません。そのため、書類、配信用コンテンツ、分析用データなど、容量を気にせずにどんどん格納することができます。
また、 AWS の様々なサービス1 から出力されるログデータは S3 に保存できるようになっています。なので、ログデータはとりあえず S3 に溜め込んで、その後 各種分析用のサービス2 を用いて分析する、というところまでがユースケースになります。
もちろん、 とりあえず のデータ置き場として使うのもありだとは思いますが、前項で触れたように料金については事前に試算をしておいたほうが良さそうです。
ファイルシステムではない
一点注意しておきたいのが、 S3 はストレージサービスですが ファイルシステムではない ということです。 S3 に格納するデータは、バケット名とオブジェクトのキーで識別されます。なので、最初に出てきた images/sample.jpg というキーはディレクトリ構造を表しているわけではなく、あくまでも images/sample.jpg というキーでオブジェクトを識別しています。
たとえば次のようなキーで識別されるオブジェクトが存在するとします。
images/red.jpgimages/brack.jpgimages/white.jpg
これらは 同じ images ディレクトリにある というよりは、 同じ images/ プレフィックスを持っている と表現するのが正しいです。 S3 のマネジメントコンソール上ではディレクトリをたどっていくようにオブジェクトにアクセスできますが、あくまでもそれは便宜上ということです。
これを理解すると、 S3 に配置した静的サイトの index.html が補完されない理由が理解してもらえるかと思います。
Lambda@Edge で静的サイトの URL を正規化する
静的ウェブサイトのホスティング
S3 の任意のバケットに静的サイトを格納し、静的ウェブサイトのホスティング機能を利用することで、 S3 のみで静的サイトのホスティングをすることができます。この機能を利用すると、前述した index.html が補完されない問題 (仕様) は解消されます。 ただし、次のような制限・注意点があります。
- ドメイン名はバケット名とリージョンからなる値となる
- 独自ドメインを使用する場合は SSL 化できない
- パブリックアクセスが有効になる
社内向けに公開するような静的サイトの公開や、ハンズオン等の場合には便利な機能です。セキュリティの項目でも触れましたが、この機能を利用するとパブリックアクセスが有効になるため、適切にアクセス権限の設定をする必要があります。
この機能を使った静的ウェブサイトのホスティングについては以前に書いたこちらの記事も参考にしてみてください。
AWS CDK を使って独自ドメインの静的サイトを S3 でホスティングする環境を構築してみた
イベント通知による他サービスとの連携
ストレージでイベント? と思われるかもしれませんが、この機能が S3 の面白いところだなと個人的には思っています。
S3 で発生するイベントには、下記のようなものがあります。
- 新しいオブジェクトの作成イベント :
s3:ObjectCreated:* - オブジェクト削除イベント :
s3:ObjectRemoved:* - オブジェクト復元イベント :
s3:ObjectRestore:Post,s3:ObjectRestore:Completed - (レプリケーションイベント)
これらのイベントをトリガーにして、任意の Lambda 関数を実行したり、SNS 経由で Slack やメールに通知をしたりすることができます。
具体的には次のような構成が考えられます。
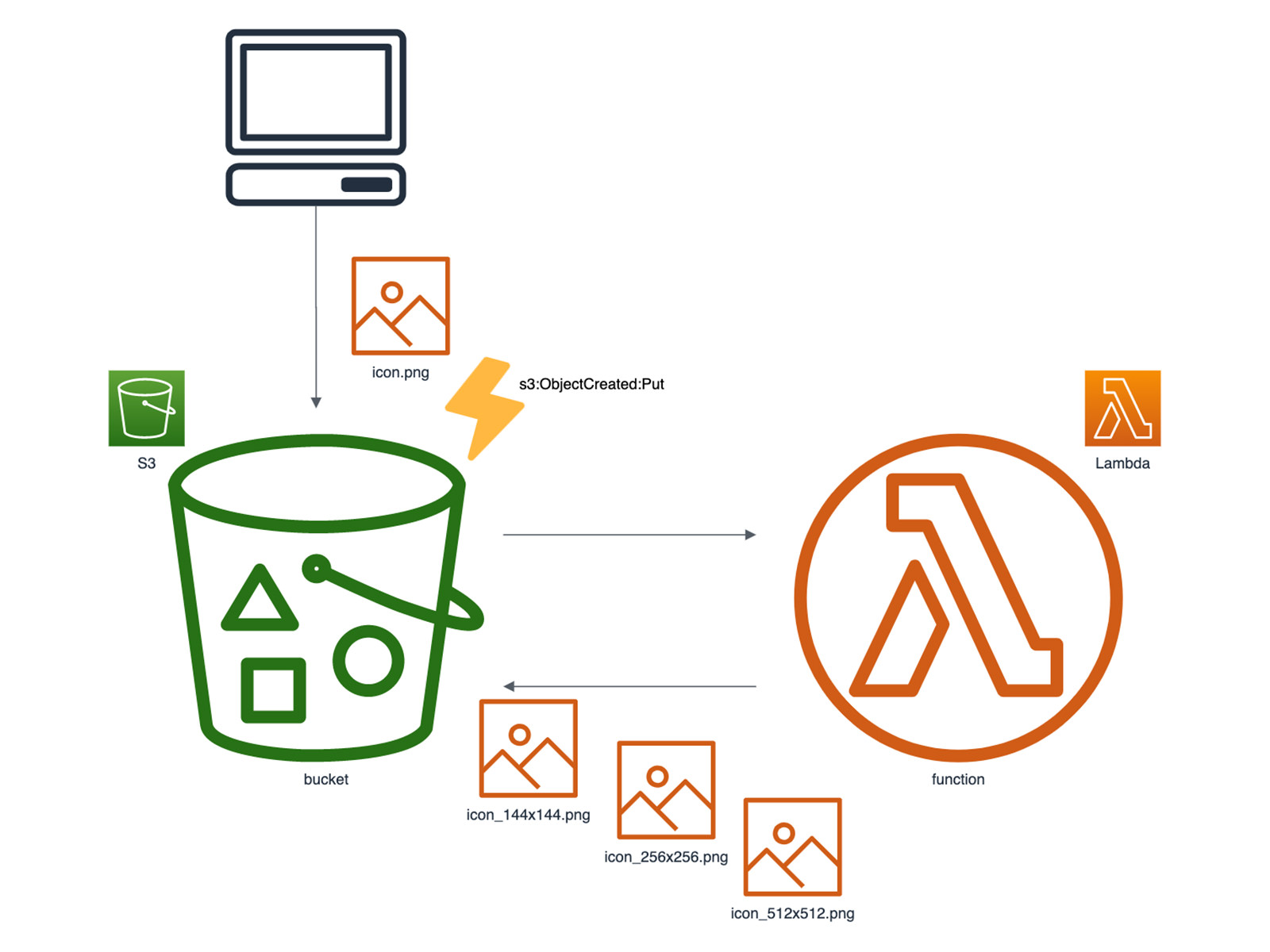
- バケットに画像が Put される
s3:ObjectCreated:Putイベント発生- イベントをトリガーに Lambda 関数を実行
- 複数サイズの画像生成、バケットへ Put
その他、簡単な翻訳のパイプラインを構築することもできるので、興味のある方は AWS の金澤さんが作成されたこちらのハンズオン資料をもとに試してみてはいかがでしょうか。
ちなみに、このハンズオンの内容を AWS CDK でやってみたというタイトルで LT もさせていただきました。(人生初 LT でした)
LT ネタの元記事になったのは以下の記事です。
オブジェクトに対して一括処理する S3 バッチオペレーション
S3 バッチオペレーション は、S3 バケットに格納されたオブジェクトに対して一括で処理を実行することができる機能です。
例えば次のような処理が考えられます。
- オブジェクトのコピー
- オブジェクトに対する特定のタグ、メタデータを付与
- 画像オブジェクトをリサイズ、またはサムネイル用のオブジェクトを生成
バッチオペレーションでは、次の手順で処理を実行します。
- インベントリレポートの作成
- ジョブの作成
- ジョブの実行
インベントリレポートの作成 では、一括処理の対象となるオブジェクトの一覧を作成します。
ジョブの作成 では、対象となるオブジェクトの一覧 (マニフェスト) と、実際に実行する処理を指定します。実際に実行する処理としては、バッチオペレーション側であらかじめ用意されている オブジェクトのコピー 、 タグの置き換え 、 ACL の置き換え 、 復元 および Lambda 関数の呼び出し を選択できます。 Lambda 関数を呼び出すことで、対象となっているオブジェクトそれぞれに対して任意の処理を実行することができます。
以前にバッチオペレーションで画像オブジェクトをリサイズしてみた記事を書いたので、こちらも参考にしてみてください。
S3 Batch Operations で S3 に保存された数万件の画像を一括でリサイズしてみた
まとめ
AWS のストレージサービス Amazon S3 の概要とユースケースについて書きました。
S3 のリリースは 2006 年ということで、 AWS の歴史のほぼ一番最初から存在しているサービスです。なんとなく容量無制限のストレージだという認識がある方がほとんどだと思いますが、ユースケースの中でで紹介したイベント通知による他サービスとの連携に関しては、れっきとしたサーバレスアーキテクチャの一部を担うサービスだということを示しています。
AWS の基本的なサービスとして挙げられることが多い Amazon S3 ですが、ただのストレージではなく、いろんな機能が詰まったサービスだなと感じました。