2020-07-11
Google Analytics Reporting API を定期実行する Lambda を CDK で構築してみた
Google Analytics の Reporting API v4 を使って定期的に PV ランキングを生成して、その結果を Amazon S3 にエクスポートする処理を AWS Lambda で実装し、諸々の構成を AWS CDK を使って管理するようなものを作ってみました。
PV 数の取得までは以前にもやっていたので、今回はそれを Lambda で実装、結果を S3 にエクスポートするようにしてみました。
[Python] Google Analytics Reporting API v4 で直近一週間のページごとの PV 数を取得する
目次
概要
- Google Analytics Reporting API で直近一週間の各ページごとの PV 数を取得
- 上位 5 件について、ページの URL とタイトルを保持した情報を JSON 形式にして S3 バケットに PUT
- この処理を、 Amazon EventBridge で定期的に実行
以上の処理をする構成を、 AWS CDK を使って実装しました。
構成図としては次のようになります。
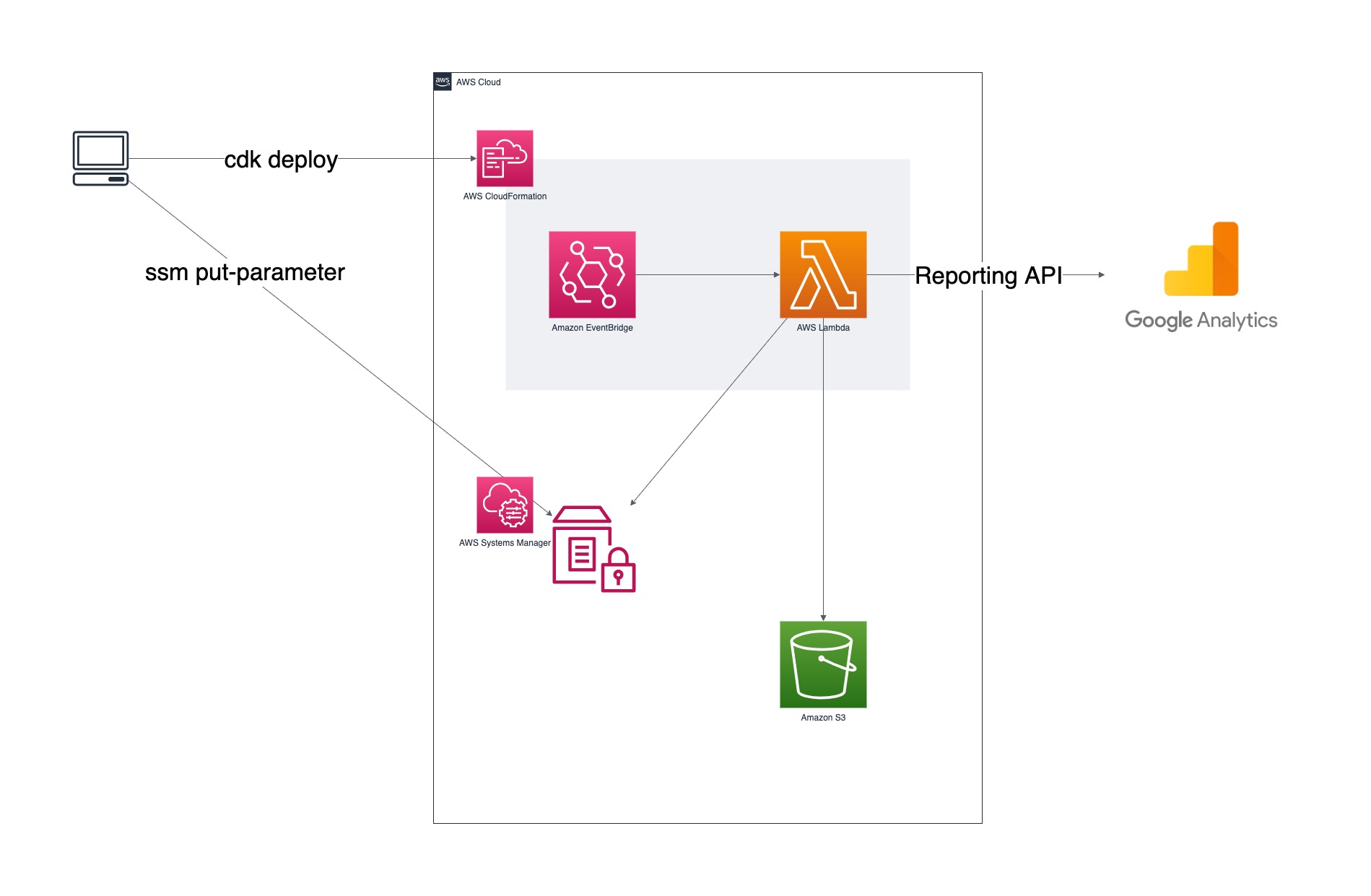
PUT 対象となる S3 バケットは既に存在しているものとして、 CDK での管理から除外しています。また、 Google のサービスアカウントキーについては、ローカル環境から AWS CLI で SSM のパラメータストアに PUT するものとして、こちらも CDK での管理から除外しています。
なので CDK で管理するリソースは、 EventBridge のルールと Lambda 関数 (とそれに付随する IAM ポリシー) ということになります。
前提
- Reporting API v4 が有効になっている
- サービスアカウントが作成されている
- サービスアカウントの認証情報 (
client_secrets.json) が手元にある
上記の準備については下記の公式レイファレンスを参照してください。
実装
詳細については GitHub のリポジトリを参照してもらえればと思うので、ここでは Lambda 関数の中身と CDK の記述について簡単に説明します。
https://github.com/michimani/export-pv-rank
Lambda 関数
Lambda 関数は Python 3.7 で実装しています。関数の中身の前に、 CDK プロジェクト内でのディレクトリ構成について書いておきます。
CDK プロジェクト内でのディレクトリ構成
今回は Google Analytics の Reporting API を使うということで、下記のモジュールをインストールしています。
google-api-python-client
google-auth-httplib2
google-auth-oauthlibまた、 Reporting API では一回で各ページのタイトルまで取得できないので、上位 5 件のページタイトルを取得するために requests モジュールもインストールしています。
リポジトリ内のディレクトリ構成としては、直下に lambda ディレクトリを作成し、その中は次のような構成としています。
lambda
├── dist
├── requirements.txt
└── src
└── fetch_rank.pyあとで書きますが、デプロイ時には dist ディレクトリを Lambda のデプロイパッケージ用のディレクトリとして使ってデプロイをします。
関数の実装内容
Lambda 関数の実装は次のようになっています。
from google.oauth2 import service_account
from googleapiclient.discovery import build
import boto3
import json
import logging
import os
import re
import traceback
import requests
SCOPES = ['https://www.googleapis.com/auth/analytics.readonly']
CLIENT_SECRET_SSM_KEY = os.environ.get('CLIENT_SECRET_SSM_KEY')
VIEW_ID = os.environ.get('VIEW_ID')
OUT_S3_BUCKET = os.environ.get('OUT_S3_BUCKET')
OUT_JSON_KEY = os.environ.get('OUT_JSON_KEY')
SITE_BASE_URL = os.environ.get('SITE_BASE_URL')
s3 = boto3.resource('s3')
ssm = boto3.client('ssm')
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def get_ssm_param(key):
# type: (str) -> str
""" Get parameter fron SSM Parameter Store.
Args:
key: string for SSM parameter store key
Returns:
string
"""
response = ssm.get_parameters(
Names=[
key,
],
WithDecryption=True
)
return response['Parameters'][0]['Value']
def initialize_analyticsreporting():
# type: () -> build
"""Initializes an Analytics Reporting API V4 service object.
Returns:
An authorized Analytics Reporting API V4 service object.
"""
client_secret_string = get_ssm_param(CLIENT_SECRET_SSM_KEY)
client_secret = json.loads(client_secret_string)
credentials = service_account.Credentials.from_service_account_info(
client_secret, scopes=SCOPES)
# Build the service object.
analytics = build('analyticsreporting', 'v4',
credentials=credentials,
cache_discovery=False)
return analytics
def get_report(analytics):
# type: (build) -> dict
"""Queries the Analytics Reporting API V4.
Args:
analytics: An authorized Analytics Reporting API V4 service object.
Returns:
The Analytics Reporting API V4 response.
"""
return analytics.reports().batchGet(
body={
'reportRequests': [
{
'viewId': VIEW_ID,
'dateRanges': [{'startDate': '7daysAgo', 'endDate': 'yesterday'}],
'metrics': [{'expression': 'ga:pageviews'}],
'dimensions': [{'name': 'ga:pagePath'}]
}]
}
).execute()
def calc(response):
# type: (dict) -> ()
"""Calculate page views of each page path.
Args:
response: The Analytics Reporting API V4 response.
"""
calc_res = dict()
pv_summary = []
report = response.get('reports', [])[0]
for report_data in report.get('data', {}).get('rows', []):
# get page path
page_path = report_data.get('dimensions', [])[0]
# ignore query parameters
page_path = re.sub(r'\?.+$', '', page_path)
# get page view
page_view = int(report_data.get('metrics', [])[0].get('values')[0])
if page_path in calc_res:
calc_res[page_path] += page_view
else:
calc_res[page_path] = page_view
for path in calc_res:
pv_summary.append({
'page_path': path,
'page_views': calc_res[path]
})
# sort by page views
pv_summary.sort(
key=lambda path_data: path_data['page_views'], reverse=True)
return pv_summary
def report_to_rank(report, count=5):
# type: (list) -> list
""" Convert report data to ranking data
Args:
report: list object to convert
count: number of ranking post. default is 5
Returns:
list
"""
if count == 0 or len(report) < count:
count = 5
rank_tmp = report[:count]
rank = list()
try:
for rt in rank_tmp:
post_url = SITE_BASE_URL + rt['page_path']
rank.append({
'post_url': post_url,
'post_title': get_post_title(post_url)})
except Exception:
print('An error occured in getting post title process.')
print(traceback.format_exc())
return rank
def get_post_title(post_url):
# type: (str) -> str
""" Get post title from post url
Args:
post_url: URL of the post
Returns:
string
"""
post_title = ''
try:
res = requests.get(post_url)
body = res.text
post_title = re.sub(r'[\s\S]+<title>(.*)<\/title>[\s\S]+', r'\1', body)
except Exception:
print(f'Failed to get post title of "{post_url}"')
print(traceback.format_exc())
return post_title
def put_to_s3(data, key):
# type: (dict, str) -> ()
""" Put object to S3 bucket
Args:
data: dict or list object to put as JSON.
key: object key
"""
try:
s3obj = s3.Object(OUT_S3_BUCKET, key)
body = json.dumps(data, ensure_ascii=False)
s3obj.put(
Body=body,
ContentType='application/json;charset=UTF-8',
CacheControl='public, max-age=1209600')
except Exception:
logger.error('Put count data failed: %s', traceback.format_exc())
def main(event, context):
analytics = initialize_analyticsreporting()
response = get_report(analytics)
summary = calc(response)
rank = report_to_rank(summary)
put_to_s3(rank, OUT_JSON_KEY)
if __name__ == '__main__':
print('Running at local...\n\n')
analytics = initialize_analyticsreporting()
response = get_report(analytics)
summary = calc(response)
rank = report_to_rank(summary)
print(json.dumps(rank, indent=2, ensure_ascii=False))ほぼ 前回 と同じですが、上位 5 件のページタイトルについては requests を使って取得しています。
また、 事前に client_secrets.json の情報を SSM パラメータストアに登録しておき、 Lambda 関数内で取得して利用しています。
そして、最後には S3 バケットに PUT しています。
ローカルで実行する際には、 S3 バケットに PUT するのではなく標準出力に生成された JSON を出力します。
CDK
続いて CDK のメインとなるスタックの記述についてです。 CDK については TypeScript で記述しています。
環境依存の値については、次のような stac-config.json にまとめて、そこから値を取得して利用しています。
{
"lambda": {
"env": {
"client_secret_ssm_key": "google-client-secret",
"view_id": "00000000",
"out_s3_bucket": "<aleady-exists-your-bucket>",
"out_json_key": "data/rank.json",
"site_base_url": "<your-site-base-url>"
}
},
"event_bridge": {
"cron_expression": "0 15 * * ? *"
}
}今回はシンプルな構成なので、スタックは分割せず一つのファイル lib/export-pv-rank-stack.ts で書いています。
import * as cdk from '@aws-cdk/core';
import lambda = require('@aws-cdk/aws-lambda');
import iam = require('@aws-cdk/aws-iam');
import events = require('@aws-cdk/aws-events');
import targets = require('@aws-cdk/aws-events-targets');
import fs = require('fs');
export class ExportPvRankStack extends cdk.Stack {
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const stackConfig = JSON.parse(fs.readFileSync('stack-config.json', {encoding: 'utf-8'}));
// Lambda function
const lambdaFn = new lambda.Function(this, 'fetchRank', {
code: new lambda.AssetCode('lambda/dist'),
runtime: lambda.Runtime.PYTHON_3_7,
handler: 'fetch_rank.main',
timeout: cdk.Duration.seconds(300),
environment: {
'CLIENT_SECRET_SSM_KEY': stackConfig['lambda']['env']['client_secret_ssm_key'],
'VIEW_ID': stackConfig['lambda']['env']['view_id'],
'OUT_S3_BUCKET': stackConfig['lambda']['env']['out_s3_bucket'],
'OUT_JSON_KEY': stackConfig['lambda']['env']['out_json_key'],
'SITE_BASE_URL': stackConfig['lambda']['env']['site_base_url'],
}
});
lambdaFn.addToRolePolicy(new iam.PolicyStatement({
actions: [
's3:PutObject',
'ssm:DescribeParameters',
],
resources: ['*']
}));
lambdaFn.addToRolePolicy(new iam.PolicyStatement({
actions: [
'ssm:GetParameter',
'ssm:GetParameters',
'ssm:GetParameterHistory',
'ssm:GetParametersByPath',
],
resources: ['arn:aws:ssm:*']
}));
// EventBridge rule
const fetchPvRanking = new events.Rule(this, 'FetchPvRanking', {
schedule: events.Schedule.expression(`cron(${stackConfig.event_bridge.cron_expression})`)
});
fetchPvRanking.addTarget(new targets.LambdaFunction(lambdaFn));
}
}stac-config.json では Lambda 関数用の環境変数も保持しているので、 Lambda 関数オブジェクトを生成する際に environment で指定しています。
前述しましたが、今回は外部モジュールを使用しているため、それらを Lambda のデプロイパッケージに含める必要があります。 CDK では 次のようにパッケージとするディレクトリを指定することで実現できます。
new lambda.AssetCode('lambda/dist')これを new lambda.Function() の code に渡せばオッケーです。
デプロイ
CDK のデプロイ自体は cdk synth からの cdk deploy コマンドで完了しますが、その前に少し準備をします。
Python の外部モジュールのインストール
今回は Python の外部モジュールを使用するので、それらをデプロイパッケージ用のディレクトリ lambda/dist にインストールします。
$ pip3 install --upgrade -r ./lambda/requirements.txt -t ./lambda/dist/本来であれば Lambda の実行環境である Amazon Linux 上でインストールしたモジュールを使うべきですが、今回は OS 依存となるようなモジュールを含まないためローカル環境でインストールしています。
ちなみに、画像処理用のモジュールである Pillow については OS 依存となるため、しっかりと環境を用意してインストールする必要があります。
AWS Lambda で Pillow を使おうとしたらハマった
あとは、 lambda/src 内にある関数本体となるスクリプトも lambda/dist にコピーしておきます。
$ cp -f ./lambda/src/fetch_rank.py ./lambda/dist/これで準備は完了です。
CDK のデプロイ
$ cdk synthで CLoudFormation テンプレートを生成して
$ cdk deployで デプロイします。
今回は IAM に関する変更・追加が発生するため、デプロイ時に確認されます。
このプロジェクトの使い所
最後に、このプロジェクトの使い所について説明します。
ブログでよくある「最近読まれている記事」みたいなものを静的サイトでも実現したいと思い、Google Analytics Reporting API v4 を使って直近一週間のページごとの PV 数を取得してみました。取得したデータを JSON とかで保持しておけば、前日までのデータで PV ランキングが作成できそうです。
これまた 前回 のブログで冒頭で書いていた内容なんですが、まさにこれを実現するためなんです。
静的サイトではあらかじめ各ページが HTML で生成されているため、動的な情報を表示するためには工夫が必要です。 SNS でのシェア数なども同じで、実際にこのブログでは各記事の はてブ数 を定期的に取得して JSON ファイルとして生成し、ページ表示時に JavaScript でその値を取得・表示させています。
Hugo で作成したブログの各記事内に Lamnda と S3 を使って はてなブックマークのブクマ件数を表示させてみた
今回はこれと同様の考えで、閲覧数ランキングを作りたいという思いで作りました。なので、同じように静的サイトでページの閲覧数ランキングを作りたいという方には参考になるかもしれません。
まとめ
Google Analytics の Reporting API v4 を使って PV ランキングを生成して、その結果を Amazon S3 にエクスポートする処理を AWS Lambda で実装し、諸々の構成を AWS CDK を使って管理するようなものを作ってみた話でした。
静的サイトで動的な情報を表示させるときの参考になれば幸いです。