2020-08-29
続・Amazon Rekognition を使ってスマブラ SP のキャプチャ画像から世界戦闘力を抜き出す
みなさんスマブラやってますか?前回、キャプチャ画像から世界戦闘力の値を抜き出しましたが、今回はその続編です。
前回の記事。
Amazon Rekognition を使ってスマブラ SP のキャプチャ画像から世界戦闘力を抜き出す
概要
前回に引き続いて、今回は次のことを試します。
- キャラクターの判別
- Amazon Rekognition の DetectText の制限 (仕様) への対応
- 検出された情報をまとめる
キャラクターの判別
Amazon Rekognition の仕様として、日本語のテキストは抽出することができません。つまり、キャプチャ画像から対象のキャラクターを名前で判別することができません。名前での判別ができないので、キャラクターのサムネイル画像のバイト文字列で判別してみます。
対象のキャラクターのサムネイルはこの部分です。
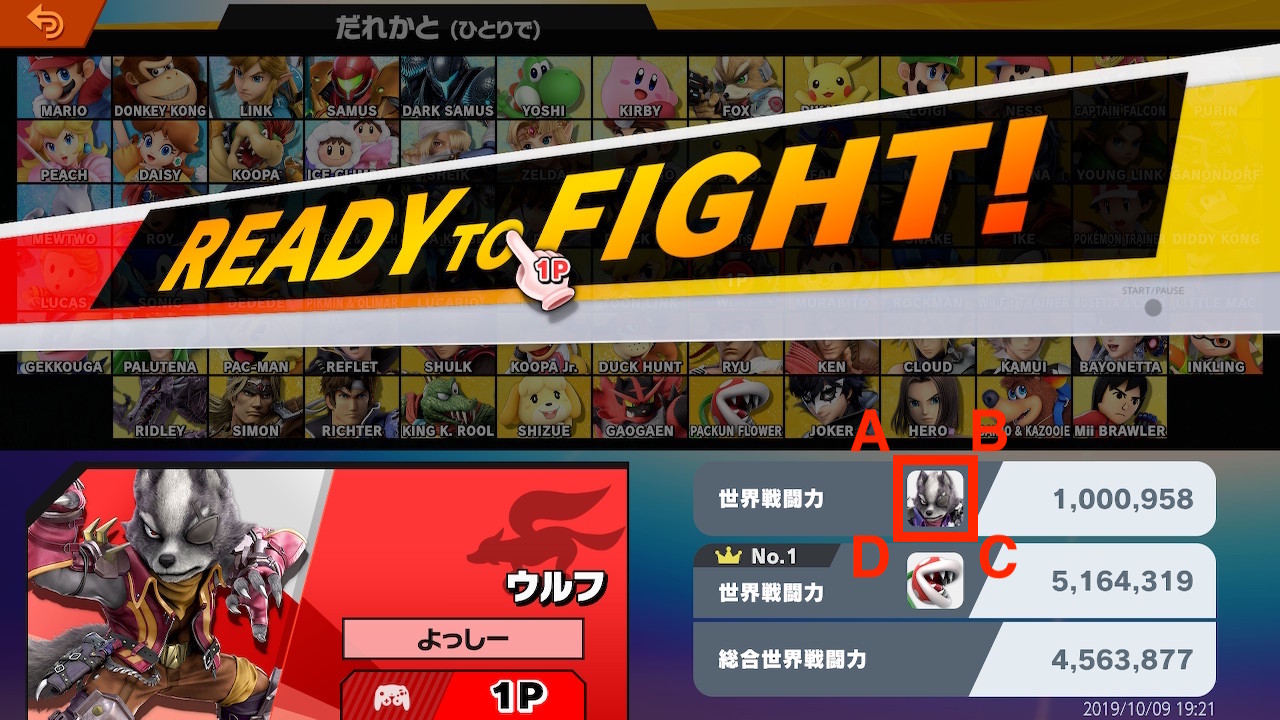
キャプチャ画像のサイズは 1260x640 (px) なので、この部分の座標 (左上が (0,0)) は次のようになります。
A : (911, 474)
B : (959, 474)
C : (959, 522)
D : (911, 522)この部分をトリミングするには、 Python の opencv-python モジュールを使います。(Python のバージョンは 3.7.x とします)
$ pip install opencv-pythonキャラクターの判別には、トリミングした画像のバイト文字列を使いますが、そのままだと長すぎるのでハッシュ値で判別することにします。
トリミングして画像のハッシュ値を取得するコードは次の通り。
import cv2
import hashlib
import os
import sys
THUMBNAIL_DIR = './char_thumb'
character_area = {
'A': {'X': 911, 'Y': 474},
'B': {'X': 959, 'Y': 474},
'C': {'X': 959, 'Y': 522},
'D': {'X': 911, 'Y': 522},
}
def get_character_hash(image_path):
img = cv2.imread(image_path)
trimed = img[
character_area['A']['Y']: character_area['D']['Y'],
character_area['A']['X']: character_area['C']['X']]
trimed_bytes = trimed.tobytes()
trimed_hash = hashlib.sha1(trimed_bytes).hexdigest()
thumb_path = f'{THUMBNAIL_DIR}/{trimed_hash}.jpg'
if os.path.exists(thumb_path) is False:
cv2.imwrite(thumb_path, trimed)
return trimed_hash
if __name__ == '__main__':
image_path = sys.argv[1]
character_hash = get_character_hash(image_path)
print(character_hash)次のようにして実行すると、キャラクター画像のハッシュ値が出力され、サムネイル用のディレクトリにトリミングした画像が生成されます。
$ python trim_img.py 2020082121055400-0E7DF678130F4F0FA2C88AE72B47AFDF.jpg
e6bc228bbea1f0d9034cbec36871df87628d9daf
同じキャラクターの別のキャプチャ画像で何度か試しましたが、ハッシュ値が異なることはなかったので、キャラクターはこれで判別できそうです。
Amazon Rekognition の DetectText の制限 (仕様) への対応
Amazon Rekognition の DetectText の制限 (仕様) として、ひとつの画像から検出できるテキストの要素数には上限があります。
A word is one or more ISO basic latin script characters that are not separated by spaces. DetectText can detect up to 50 words in an image.
テキストの検出は画像の左上から始まっているようで、画像内にこの上限を超えるテキスト要素が存在している場合、画像の下の方のテキストは検出されないことになります。
例えば、次のようなキャプチャ画像では世界戦闘力の部分にたどり着くまでに検出数の上限に達しており、世界戦闘力の値を検出することができません。
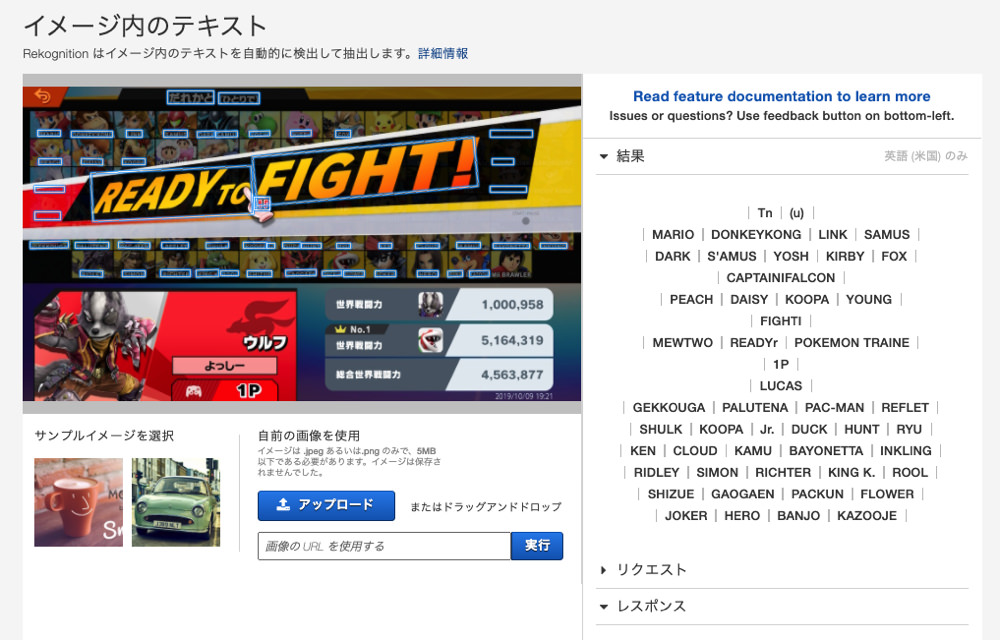
この問題を回避するために、キャプチャを 4 分割して右下の部分のみを検出対象画像にしたいと思います。
これを実現するためには、先程と同様に opencv-python モジュールでサムネイル画像をトリミングします。
Rekognition には画像のバイト文字列を渡すので、キャプチャ画像の右下をトリミングした画像を一旦生成し、バイト文字列を取得します。その後、トリミングした画像は不要になるので削除します。…というのを次の関数で処理します。
TMP_DIR = './tmp'
def get_bytes_of_image(image_path):
img = cv2.imread(image_path)
trimed = img[
360: 720,
640: 1280
]
ts = str(time.time())
trimed_tmp_path = f'{TMP_DIR}/{ts}.jpg'
cv2.imwrite(trimed_tmp_path, trimed)
with open(trimed_tmp_path, mode='rb') as img:
image_bytes = img.read()
os.remove(trimed_tmp_path)
return image_bytes世界戦闘力の描画エリア調整
Rekognition にわたす画像が元のキャプチャの右下部分になったので、 DetectText のレスポンスから世界戦闘力を抜き出すための描画エリアを調整します。
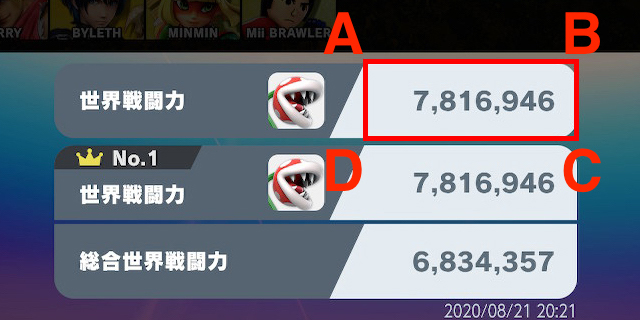
トリミングされた画像は 640x320 (px) になっており、 ABCD の各座標は次のようになっています。
A : (366, 60)
B : (576, 60)
C : (576, 138)
D : (366, 138)これを画像サイズに対する割合に変換します。
A : (0.57187, 0.1875)
B : (0.9, 0.1875)
C : (0.9, 0.43125)
D : (0.57187, 0.43125)あとは前回と同じです。
検出された情報をまとめる
最後に、キャプチャ画像から得られた情報をひとつのオブジェクトとしてまとめます。まとめる情報としては次の通りです。
- キャラクターのハッシュ値
- キャプチャ画像の取得日時
- 世界戦闘力の値
これらを JSON で出力するように改修したのが下記のコードです。
import boto3
import cv2
import datetime
import hashlib
import json
import os
import re
import sys
import time
TMP_DIR = './tmp'
THUMBNAIL_DIR = './char_thumb'
reko = boto3.client('rekognition')
target_area = {
'A': {'X': 0.57187, 'Y': 0.1875},
'B': {'X': 0.9, 'Y': 0.1875},
'C': {'X': 0.9, 'Y': 0.43125},
'D': {'X': 0.57187, 'Y': 0.43125},
}
character_area = {
'A': {'X': 911, 'Y': 474},
'B': {'X': 959, 'Y': 474},
'C': {'X': 959, 'Y': 522},
'D': {'X': 911, 'Y': 522},
}
def get_datetime_from_image_path(image_path):
datetime_part = re.sub(r'.*(\d{16}).*', r'\1', image_path)[:14]
dt = datetime.datetime.strptime(datetime_part, '%Y%m%d%H%M%S')
datetime_str = '{0:%Y-%m-%d %H:%M:%S}'.format(dt)
return datetime_str
def get_character_hash(image_path):
img = cv2.imread(image_path)
trimed = img[
character_area['A']['Y']: character_area['D']['Y'],
character_area['A']['X']: character_area['C']['X']]
trimed_bytes = trimed.tobytes()
trimed_hash = hashlib.sha1(trimed_bytes).hexdigest()
thumb_path = f'{THUMBNAIL_DIR}/{trimed_hash}.jpg'
if os.path.exists(thumb_path) is False:
cv2.imwrite(thumb_path, trimed)
return trimed_hash
def get_bytes_of_image(image_path):
img = cv2.imread(image_path)
trimed = img[
360: 720,
640: 1280
]
ts = str(time.time())
trimed_tmp_path = f'{TMP_DIR}/{ts}.jpg'
cv2.imwrite(trimed_tmp_path, trimed)
with open(trimed_tmp_path, mode='rb') as img:
image_bytes = img.read()
os.remove(trimed_tmp_path)
return image_bytes
def detect_text(image_path):
image_bytes = get_bytes_of_image(image_path)
return reko.detect_text(
Image={
'Bytes': image_bytes
}
)
def get_smash_power(image_path):
smash_power = 0
detect_res = detect_text(image_path)
for detected in detect_res['TextDetections']:
polygon = detected['Geometry']['Polygon']
if polygon[0]['X'] > target_area['A']['X'] and polygon[0]['Y'] > target_area['A']['Y'] \
and polygon[1]['X'] < target_area['B']['X'] and polygon[1]['Y'] > target_area['B']['Y'] \
and polygon[2]['X'] < target_area['C']['X'] and polygon[2]['Y'] < target_area['C']['Y'] \
and polygon[3]['X'] > target_area['D']['X'] and polygon[3]['Y'] < target_area['D']['Y']:
smash_power = int(detected['DetectedText'].replace(',', ''))
return smash_power
def generate_smash_power_item(image_path):
# Datetime of data
datetime_str = get_datetime_from_image_path(image_path)
# Get Smash Power via Amazon Rekognition
smash_power = get_smash_power(image_path)
# Get character hash (and Generate character thumbnail)
character_hash = get_character_hash(image_path)
return {
'character_hash': character_hash,
'capture_datetime': datetime_str,
'power': smash_power
}
if __name__ == '__main__':
image_path = sys.argv[1]
smash_power_item = generate_smash_power_item(image_path)
print(json.dumps(smash_power_item, indent=2, ensure_ascii=False))これを実行すると、次のような結果が得られます。
$ python detect_smash_power.py 2019100921045700-0E7DF678130F4F0FA2C88AE72B47AFDF.jpg
{
"character_hash": "06e200a624eab0babac0ea3fee6325efcb3dae05",
"capture_datetime": "2019-10-09 21:04:57",
"power": 1000958
}コードはこちら。
Use Amazon Rekognition to detect world strength from captured images of Smash Bros SPECIAL. (part 2)
まとめ
Amazon Rekognition を使ってスマブラ SP の世界戦闘力を抜き出してみました、という 前回 の記事から、今回はキャラクターの判別とデータのまとめを試してみました。その際に Rekognition の制限 (仕様) にも対応してみました。
これでデータの生成準備が整ったので、キャラクターごとの世界戦闘力の推移をグラフ化できる未来も近そうです。