2020-02-22
JAWS-UG 初心者支部#24 サーバレスハンズオン勉強会の宿題をやってみた #jawsug_bgnr #jawsug
先日開催された JAWS-UG 初心者支部#24 サーバレスハンズオン勉強会で宿題になっていた課題をやってみました。内容としては、文字起こし & 翻訳のパイプライン処理です。
前半部分は当日の様子と、ハンズオンの内容について書いています。宿題部分については後半に書いています。
目次
当日の様子
当初は現地での参加を予定していましたが、昨今の諸々の情勢からリモート枠に変更し、自宅からリモートで参加させていただきました。
現地開催についても様々な検討事項や懸念等あったかと思いますが、リモート含め開催されたことに感謝いたします。ありがとうございました。
イベントの詳細については connpass のページを参照してください。今回使用した資料等もアップされています。
また、当日の様子については、ハッシュタグ #jawsug_bgnr および #jawsug でツイートされており、 Togetter にもまとめられていました。
ハンズオンの概要
当時のハンズオンは以下の内容でした。
- AWS Lambda で 日 -> 英 翻訳する
- 翻訳 Web API を作る
- 文字起こし + 翻訳パイプラインを作る
簡単に概要を書いておきます。
なお、ハンズオンの進行に使用されたメインのスライド、およびソースコードについては公開されています。
- [JAWS−UG 初心者支部 #24] サーバーレスクイックスタート: 手を動かしながら学ぶサーバーレスはじめの一歩 #jawsug #jawsug_bgnr / JAWS−UG-bgnr 24 - Serverless Quick Start hands-on - Speaker Deck
- ketancho/aws-serverless-quick-start-hands-on: “サーバーレスクイックスタート: 手を動かしながら学ぶサーバーレスはじめの一歩” のサンプルコードです
1. AWS Lambda で 日 -> 英 翻訳する
AWS の翻訳サービス Amazon Translate の API を実行する Lambda 関数を作成して、日本語から英語への翻訳します。
実行は Lambda のマネジメントコンソール上からテストする形で、テストに使用するイベントには Amazon API Gateway AWS Proxy テンプレートを使用しました。
ただし、翻訳する本文はこの時点ではハードコーディングされているもので、とりあえず Amazon Translate で翻訳できるよね、とういことを確認しました。
下記のような Lambda 関数を使用して実行しました。
import json
import boto3
def lambda_handler(event, context):
translate = boto3.client('translate')
input_text = '順調ですか?'
response = translate.translate_text(
Text=input_text,
SourceLanguageCode='ja',
TargetLanguageCode='en'
)
output_text = response.get('TranslatedText')
return {
'statusCode': 200,
'body': json.dumps({
'output_text': output_text
})
}2. 翻訳 Web API を作る
先ほどの Lambda 関数を下記のように変更し、 API Gateway のイベントから翻訳対象の文字列を取得できるように変更しました。
- input_text = '順調ですか?'
+ input_text = event['queryStringParamaters]['input_text]マネジメントコンソール上で API Gateway と Lambda の繋ぎ込みをして、実際に URL に input_text パラメータを付与して翻訳結果が得られることを確認しました。
3. 文字起こし + 翻訳パイプラインを作る
音声ファイルを S3 にアップロードし、それをトリガーにして Lambda 関数を実行するというパイプラインを作成しました。
実行される Lambda 関数内では、AWS の文字起こしサービス Amazon Transcribe を使ってアップロードされた音声ファイルから文字起こしをして、その結果を S3 に出力するというパイプラインの作成です。ハンズオンで実施したのは文字起こしまでで、翻訳を含めたパイプラインについては宿題となっていました。後ほどこの部分はやってみます。
宿題の内容
ここからは宿題となっていた 文字起こし + 翻訳 のパイプラインを作成してみます。
作成するパイプラインは次のような構成です。
S3 バケットの作成
ハンズオンの手順では S3 バケットを既に作っていましたが、あらためてその部分からやってみます。
作成する S3 バケットは下記の 2 種類です。
- 音声ファイルアップロード用
jugbgnr24-transcribe-input-michimani - 文字起こし結果アウトプット用:
jugbgnr24-transcribe-output-michimani - 翻訳結果アウトプット用:
jugbgnr24-translate-output-michimani
上の図では 文字起こし結果アウトプット用 と 翻訳結果アウトプット用 が同じバケットを指しているような形になっていますが、別のバケットとして作成します。
$ aws s3 mb s3://jugbgnr24-transcribe-input-michimani
make_bucket: jugbgnr24-transcribe-input-michimani
$ aws s3 mb s3://jugbgnr24-transcribe-output-michimani
make_bucket: jugbgnr24-transcribe-output-michimani
$ aws s3 mb s3://jugbgnr24-translate-output-michimani
make_bucket: jugbgnr24-translate-output-michimani
$ aws s3 ls | grep jugbgnr24
2020-02-22 13:05:30 jugbgnr24-transcribe-input-michimani
2020-02-22 13:05:43 jugbgnr24-transcribe-output-michimani
2020-02-22 13:05:51 jugbgnr24-translate-output-michimani文字起こし用 Lambda 関数の作成
続いて、文字起こし用の Lambda 関数を作成します。といってもこの部分に関してはハンズオン内で使用した Lambda 関数をほぼそのまま使えます。
import json
import urllib.parse
import boto3
import datetime
s3 = boto3.client('s3')
transcribe = boto3.client('transcribe')
def lambda_handler(event, context):
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
try:
transcribe.start_transcription_job(
TranscriptionJobName= datetime.datetime.now().strftime("%Y%m%d%H%M%S") + '_Transcription',
LanguageCode='en-US',
Media={
'MediaFileUri': 'https://s3.ap-northeast-1.amazonaws.com/' + bucket + '/' + key
},
OutputBucketName='jugbgnr24-transcribe-output-michimani'
)
except Exception as e:
print(e)
print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket))
raise eLambda の実行ロールには S3 と Transcribe を操作できるポリシーをアタッチしておきます。
ハンズオンでは Lambda 関数作成時に設計図から作成する方法が紹介されていました、今回は 一から作成 を選択してしまったので、トリガーの設定をしておきます。
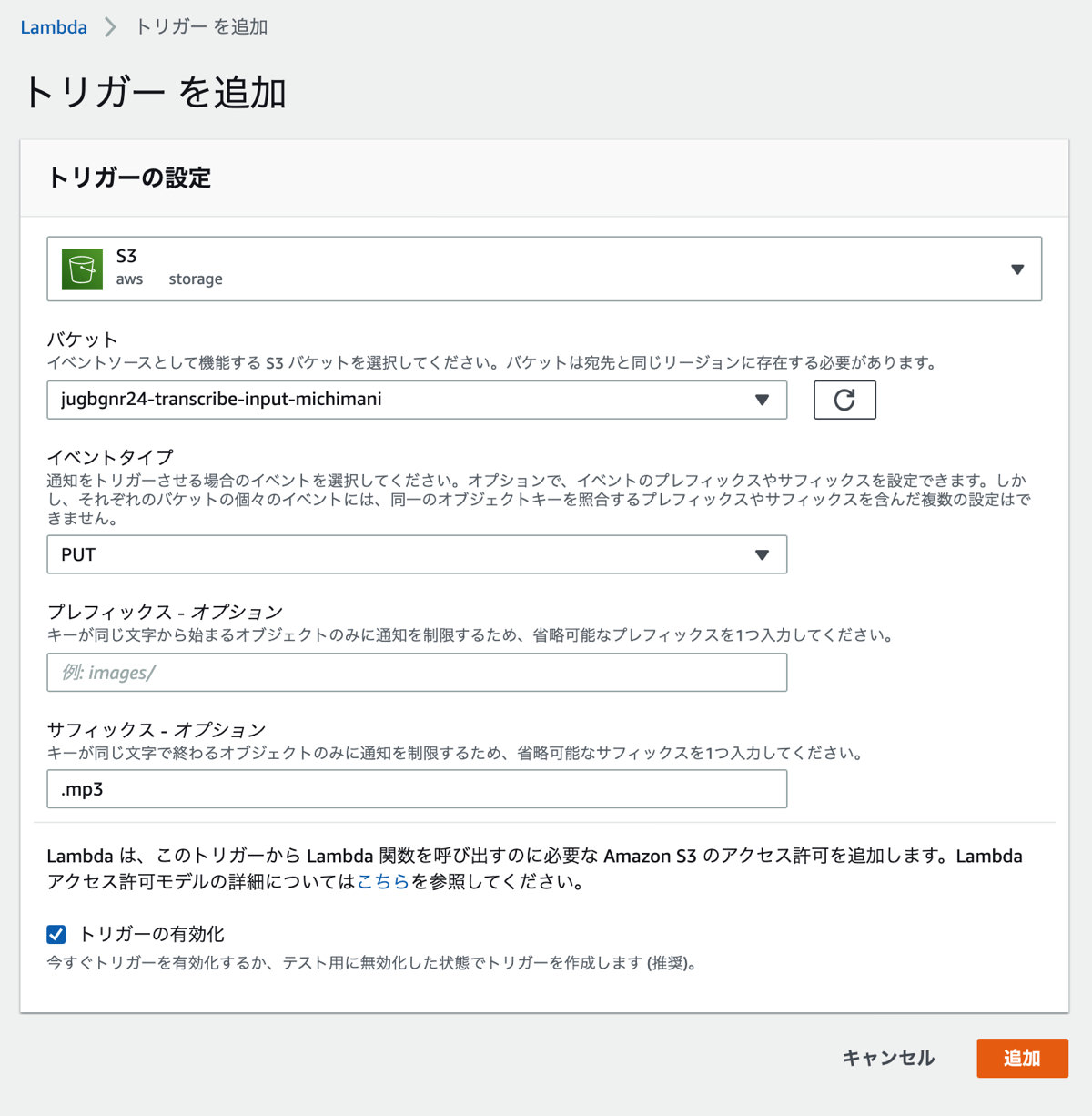
ここまではハンズオンの内容ですが、いったん処理を確認してみます。 音声ファイルは Amazon Polly のサンプルファイルを使用します。
今回使用する音声ファイルは、英語の音声で女性が話しているファイルで、長さは 4 秒ほどの音声です。
$ aws s3 cp HelloEnglish-Joanna.mp3 s3://jugbgnr24-transcribe-input-michimani
upload: ./HelloEnglish-Joanna.mp3 to s3://jugbgnr24-transcribe-input-michimani/HelloEnglish-Joanna.mp3しばらく (1 分くらい) してから文字起こし結果アウトプット用のバケット jugbgnr24-transcribe-output-michimani を確認してみます。
$ aws s3 ls s3://jugbgnr24-transcribe-output-michimani/
2020-02-22 13:21:03 2 .write_access_check_file.temp
2020-02-22 13:21:55 1879 20200222042102_Transcription.json20200222042102_Transcription.json というファイルが作成されています。 (.write_access_check_file.temp も作成されていますが、ここでは無視します)
取得して中身を確認してみます。
{
"jobName": "20200222042102_Transcription",
"accountId": "123456789012",
"results": {
"transcripts": [
{
"transcript": "Hello. Do you speak a foreign language? One language is never enough."
}
],
"items": [
{
"start_time": "0.04",
"end_time": "0.65",
"alternatives": [
{
"confidence": "0.9139",
"content": "Hello"
}
],
"type": "pronunciation"
},
{
"alternatives": [
{
"confidence": "0.0",
"content": "."
}
],
"type": "punctuation"
},
{
"start_time": "1.04",
"end_time": "1.14",
"alternatives": [
{
"confidence": "1.0",
"content": "Do"
}
],
"type": "pronunciation"
},
{
"start_time": "1.14",
"end_time": "1.27",
"alternatives": [
{
"confidence": "1.0",
"content": "you"
}
],
"type": "pronunciation"
},
{
"start_time": "1.27",
"end_time": "1.59",
"alternatives": [
{
"confidence": "1.0",
"content": "speak"
}
],
"type": "pronunciation"
},
{
"start_time": "1.59",
"end_time": "1.65",
"alternatives": [
{
"confidence": "0.9991",
"content": "a"
}
],
"type": "pronunciation"
},
{
"start_time": "1.65",
"end_time": "1.99",
"alternatives": [
{
"confidence": "1.0",
"content": "foreign"
}
],
"type": "pronunciation"
},
{
"start_time": "1.99",
"end_time": "2.59",
"alternatives": [
{
"confidence": "1.0",
"content": "language"
}
],
"type": "pronunciation"
},
{
"alternatives": [
{
"confidence": "0.0",
"content": "?"
}
],
"type": "punctuation"
},
{
"start_time": "2.88",
"end_time": "3.19",
"alternatives": [
{
"confidence": "0.9944",
"content": "One"
}
],
"type": "pronunciation"
},
{
"start_time": "3.19",
"end_time": "3.61",
"alternatives": [
{
"confidence": "0.991",
"content": "language"
}
],
"type": "pronunciation"
},
{
"start_time": "3.61",
"end_time": "3.75",
"alternatives": [
{
"confidence": "0.991",
"content": "is"
}
],
"type": "pronunciation"
},
{
"start_time": "3.75",
"end_time": "4.03",
"alternatives": [
{
"confidence": "1.0",
"content": "never"
}
],
"type": "pronunciation"
},
{
"start_time": "4.03",
"end_time": "4.48",
"alternatives": [
{
"confidence": "0.9079",
"content": "enough"
}
],
"type": "pronunciation"
},
{
"alternatives": [
{
"confidence": "0.0",
"content": "."
}
],
"type": "punctuation"
}
]
},
"status": "COMPLETED"
}色々とデータが入っていますが、 ['results']['transcripts'][0]['transcript'] の値として文字起こし結果の文字列が含まれていることがわかります。
{
"results": {
"transcripts": [
{
"transcript": "Hello. Do you speak a foreign language? One language is never enough."
}
],
}
}実際の音声ファイルでもこのように話しているので、正常に文字起こしできているようです。
翻訳用 Lambda 関数の作成
続いては、文字起こしした結果を翻訳する Lambda 関数を作成します。この関数は、文字起こし結果アウトプット用バケット jugbgnr24-transcribe-output-michimani にファイルが作成されたことをトリガーに実行され、作成されたファイル内の文字起こし結果を翻訳、そしてその結果を翻訳結果アウトプット用バケット jugbgnr24-translate-output-michimani に出力します。
それらを実現するために次のような Lambda 関数を作成します。
import json
import urllib.parse
import boto3
import datetime
s3 = boto3.client('s3')
translate = boto3.client('translate')
def lambda_handler(event, context):
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
try:
# 文字起こし結果オブジェクト (json ファイル) を取得
transcribe_result_obj = s3.get_object(Bucket=bucket, Key=key)
# json 内から文字起こし結果の文字列を取得
transcribe_result_json = json.loads(transcribe_result_obj['Body'].read().decode('utf-8'))
input_text = transcribe_result_json['results']['transcripts'][0]['transcript']
# 英語から日本語に翻訳
response = translate.translate_text(
Text=input_text,
SourceLanguageCode='en',
TargetLanguageCode='ja'
)
# 翻訳結果を S3 バケットに出力
out_bucket = 'jugbgnr24-translate-output-michimani'
out_key = datetime.datetime.now().strftime("%Y%m%d%H%M%S") + '_Translate.txt'
out_body = response.get('TranslatedText')
s3.put_object(
Bucket=out_bucket,
Key=out_key,
Body=out_body
)
except Exception as e:
print(e)
raise eLambda の実行ロールには S3 と Translate を操作できるポリシーをアタッチしておきます。
また、先ほどと同様にトリガーの設定もしておきます。
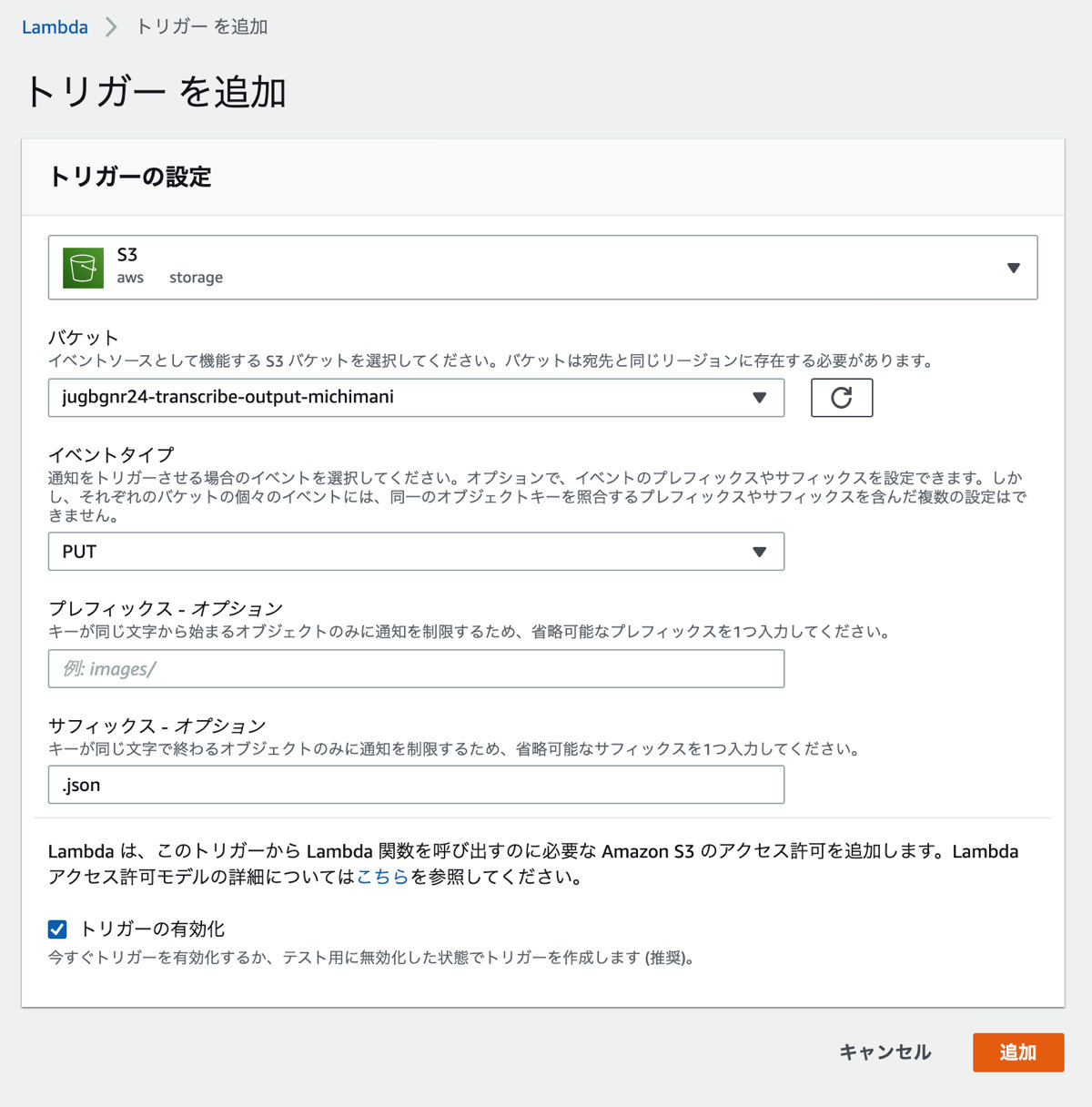
今回は簡易的に、翻訳結果をテキストファイルとして S3 バケットに出力するようにしています。
では、マネジメントコンソール上でテストイベントを作成し、テストしてみます。テンプレートは S3 の PUT イベントのテンプレートを使用します。
{
"Records": [
{
"eventVersion": "2.0",
"eventSource": "aws:s3",
"awsRegion": "ap-northeast-1",
"eventTime": "1970-01-01T00:00:00.000Z",
"eventName": "ObjectCreated:Put",
"userIdentity": {
"principalId": "EXAMPLE"
},
"requestParameters": {
"sourceIPAddress": "127.0.0.1"
},
"responseElements": {
"x-amz-request-id": "EXAMPLE123456789",
"x-amz-id-2": "EXAMPLE123/5678abcdefghijklambdaisawesome/mnopqrstuvwxyzABCDEFGH"
},
"s3": {
"s3SchemaVersion": "1.0",
"configurationId": "testConfigRule",
"bucket": {
"name": "jugbgnr24-transcribe-output-michimani",
"ownerIdentity": {
"principalId": "EXAMPLE"
},
"arn": "arn:aws:s3:::example-bucket"
},
"object": {
"key": "20200222042102_Transcription.json",
"size": 1024,
"eTag": "0123456789abcdef0123456789abcdef",
"sequencer": "0A1B2C3D4E5F678901"
}
}
}
]
}対象の S3 バケットとキーを、先ほど作成された文字起こし結果のものに変更して、テストしてみます。エラーなく正常に実行が終わったら、翻訳結果アウトプット用バケット jugbgnr24-translate-output-michimani の中を確認してみます。
$ aws s3 ls s3://jugbgnr24-translate-output-michimani
2020-02-22 13:55:35 101 20200222045534_Translate.txtテキストファイルが生成されているので、取得して中身を確認してみます。
$ cat 20200222045534_Translate.txt
こんにちは。 外国語を話せますか。 一つの言語では十分ではありません。Hello. Do you speak a foreign language? One language is never enough. の翻訳結果が出力されました。
文字起こしから通して確認してみる
これでそれぞれのパートの処理が確認できたので、最後に音声ファイルのアップロードから翻訳結果のテキストファイル出力までの流れを確認してみます。
その前に、対象の 3 つのバケットは空にしておきます。ローカルで適当に空のディレクトリを作って、そのディレクトリ内で下記のコマンドを実行しました。
$ aws s3 sync . s3://jugbgnr24-transcribe-input-michimani --delete
delete: s3://jugbgnr24-transcribe-input-michimani/HelloEnglish-Joanna.mp3
$ aws s3 sync . s3://jugbgnr24-transcribe-output-michimani --delete
delete: s3://jugbgnr24-transcribe-output-michimani/.write_access_check_file.temp
delete: s3://jugbgnr24-transcribe-output-michimani/20200222042102_Transcription.json
$ aws s3 sync . s3://jugbgnr24-translate-output-michimani --delete
delete: s3://jugbgnr24-translate-output-michimani/20200222045534_Translate.txtこれで準備ができたので、音声ファイルを PUT してみます。
$ aws s3 cp HelloEnglish-Joanna.mp3 s3://jugbgnr24-transcribe-input-michimani
upload: ./HelloEnglish-Joanna.mp3 to s3://jugbgnr24-transcribe-input-michimani/HelloEnglish-Joanna.mp3しばらく (1 分くらい) してから翻訳結果アウトプット用バケット jugbgnr24-translate-output-michimani を確認してみます。
aws s3 ls s3://jugbgnr24-translate-output-michimani
2020-02-22 14:09:24 101 20200222050923_Translate.txtテキストファイルが生成されています。取得して中身を確認してみます。
$ cat 20200222050923_Translate.txt
こんにちは。 外国語を話せますか。 一つの言語では十分ではありません。成功してますね。
念のため別の音声ファイルでも試してみたいと思います。今度は少し長い 33 秒の音声ファイルです。同じく Amazon Polly のサンプルページから取得します。
$ aws s3 cp overview_joanna_news_2.mp3 s3://jugbgnr24-transcribe-input-michimani
upload: ./overview_joanna_news_2.mp3 to s3://jugbgnr24-transcribe-input-michimani/overview_joanna_news_2.mp3今回は 2 分ほど経ってからテキストファイルが出力されました。
$ aws s3 ls s3://jugbgnr24-translate-output-michimani
2020-02-22 14:09:24 101 20200222050923_Translate.txt
2020-02-22 14:14:38 796 20200222051437_Translate.txt取得して確認してみます。
$ cat 20200222051437_Translate.txt
アマゾン Polly は、テキストを音声のような生活に変えるサービスです。音声対応製品の全く新しいカテゴリを話して構築するアプリケーションを作成できます。 Amazon Polly は、標準的な TTS ボイスに加えて、ニューラルテキストからスピーチと TTS ボイスを使用可能にし、新しい機械学習アプローチを通じて画期的なスピーチ品質を向上させます。これにより、最も自然で人間のようなテキストからスピーチを顧客に提供します。Voiceが市場に出回っています。 ニューラルTTS技術は、ニュースナレーション、ユースケースに合わせたニュースキャスターの読書スタイルもサポートしています。改行がないので見辛いですが、内容としは下記の内容になっていました。
アマゾン Polly は、テキストを音声のような生活に変えるサービスです。音声対応製品の全く新しいカテゴリを話して構築するアプリケーションを作成できます。 Amazon Polly は、標準的な TTS ボイスに加えて、ニューラルテキストからスピーチと TTS ボイスを使用可能にし、新しい機械学習アプローチを通じて画期的なスピーチ品質を向上させます。これにより、最も自然で人間のようなテキストからスピーチを顧客に提供します。Voiceが市場に出回っています。 ニューラルTTS技術は、ニュースナレーション、ユースケースに合わせたニュースキャスターの読書スタイルもサポートしています。
ちゃんと翻訳されていますね。
まとめ
JAWS-UG 初心者支部#24 サーバレスハンズオン勉強会で宿題になっていた課題 文字起こし & 翻訳のパイプライン処理 を作成してみた話でした。
サーバレス と聞くとどうしても API Gateway + Lambda のイメージが強く、 S3 をサーバレスの構成要素として考えることはほとんどありませんでした。ただ、今回のようにバケットへのオブジェクト作成をトリガーにした処理を実際に実装してみると、 S3 もサーバレスの処理の一部として普通に使えそうというか、ただのストレージとしてだけ使うのは勿体ないなという印象を持ちました。
初心者支部のハンズオンということもあり、各マネージドサービスの基本的な部分を組み合わせた形で非常に作業もしやすく、また新たにできることが増えたなと感じることができました。
去年からいろんなハンズオンに参加するようになりましたが、やはり実際に手を動かすのは大事だなと改めて感じたので、今後も積極的に現地でも、リモートでも参加していきたいと思います。